* [bitcoin-dev] Updates on Confidential Transactions efficiency
@ 2017-11-14 1:21 Gregory Maxwell
2017-11-14 9:11 ` Peter Todd
` (2 more replies)
0 siblings, 3 replies; 6+ messages in thread
From: Gregory Maxwell @ 2017-11-14 1:21 UTC (permalink / raw)
To: Bitcoin Dev
Jump to "New things here" if you're already up to speed on CT and just
want the big news.
Back in 2013 Adam Back proposed that Bitcoin and related systems could
use additive homomorphic commitments instead of explicit amounts in
place of values in transactions for improved privacy. (
https://bitcointalk.org/index.php?topic=305791.0 )
We've since adopted the name 'confidential transactions' for this
particular approach to transaction privacy.
This approach makes transaction amounts private--known only to the
sender, the receiver, and whichever parties they choose to share the
information with through sharing watching keys or through revealing
single transactions. While that, combined with pseudonymous addresses,
is a pretty nice privacy improvement in itself, it turns out that
these blinded commitments also perfectly complement CoinJoin (
https://bitcointalk.org/index.php?topic=279249.0 ) by avoiding the
issue of joins being decoded due to different amounts being used. Tim
Ruffing and Pedro Moreno-Sanchez went on to show that CJ can be
dropped into distributed private protocols for CoinJoin (
http://fc17.ifca.ai/bitcoin/papers/bitcoin17-final6.pdf ) which
achieve the property where no participant learns which output
corresponds to which other participant.
The primary advantage of this approach is that it can be constructed
without any substantial new cryptographic assumptions (e.g., only
discrete log security in our existing curve), that it can be high
performance compared to alternatives, that it has no trusted setup,
and that it doesn't involve the creation of any forever-growing
unprunable accumulators. All major alternative schemes fail multiple
of these criteria (e.g., arguably Zcash's scheme fails every one of
them).
I made an informal write-up that gives an overview of how CT works
without assuming much crypto background:
https://people.xiph.org/~greg/confidential_values.txt
The main sticking point with confidential transactions is that each
confidential output usually requires a witness which shows that the
output value is in range. Prior to our work, the smallest range
proofs without trusted setup for the 0-51 bit proofs needed for values
in Bitcoin would take up 160 bytes per bit of range proved, or 8160
bytes needed for 51 bits--something like a 60x increase in transaction
size for a typical transaction usage.
I took Adam's suggestion and invented a number of new optimizations,
and created a high performance implementation. (
https://github.com/ElementsProject/secp256k1-zkp/tree/secp256k1-zkp/src/modules/rangeproof
). With these optimizations the size is reduced to 128 bytes per two
bits plus 32 bytes; about 40% of the prior size. My approach also
allowed a public exponent and minimum value so that you could use a
smaller range (e.g., 32 bits) and have it cover a useful range of
values (though with a little privacy trade-off). The result could give
proof sizes of about 2.5KB per output under realistic usage. But this
is still a 20x increase in transaction size under typical usage--
though some in the Bitcoin space seem to believe that 20x larger
blocks would be no big deal, this isn't a view well supported by the
evidence in my view.
Subsequent work has been focused on reducing the range proof size further.
In our recent publication on confidential assets (
https://blockstream.com/bitcoin17-final41.pdf ) we reduce the size to
96*log3(2)*bits + 32, which still leaves us at ~16x size for typical
usage. (The same optimizations support proofs whose soundness doesn't
even depend on the discrete log assumption with the same size as the
original CT publication).
-- New things here --
The exciting recent update is that Benedikt Bünz at Standford was able
to apply and optimize the inner product argument of Jonathan Bootle to
achieve an aggregate range proof for CT with size 64 * (log2(bits *
num_outputs)) + 288, which is ~736 bytes for the 64-bit 2-output case.
This cuts the bloat factor down to ~3x for today's traffic patterns.
Since the scaling of this approach is logarithmic with the number of
outputs, use of CoinJoin can make the bloat factor arbitrarily small.
E.g., combining 64 transactions still only results in a proof under
1.1KB, so in that case the space overhead from the range proof is
basically negligible.
The log scaling in the number of range-bits also means that unlike the
prior construction there is little reason to be skimpy with the number
of bits of range at the potential expense of privacy: covering the
full range of possible values takes only slightly longer proofs than
covering a short range. This scheme also has a straightforward and
efficient method for multi-party computation, which means that the
aggregates can be used in all-party-private coinjoins like the value
shuffle work mentioned above.
Unlike prior optimizations, verification in this new work requires
computation which is more than linear in the size of the proof (the
work is linear in the size of the statement being proved). So it's
likely that in spite of the small proofs the verification will be
similar in speed to the prior version, and likely that computation
will be the bottleneck. Andrew, Pieter, Jonas Nick, and I are working
on an optimized implementation based on libsecp256k1 so we'll know
more precise performance numbers soon.
This work also allows arbitrarily complex conditions to be proven in
the values, not just simple ranges, with proofs logarithmic in the
size of the arithmetic circuit representing the conditions being
proved--and still with no trusted setup. As a result it potentially
opens up many other interesting applications as well.
The pre-print on this new work is available at https://eprint.iacr.org/2017/1066
^ permalink raw reply [flat|nested] 6+ messages in thread* Re: [bitcoin-dev] Updates on Confidential Transactions efficiency 2017-11-14 1:21 [bitcoin-dev] Updates on Confidential Transactions efficiency Gregory Maxwell @ 2017-11-14 9:11 ` Peter Todd 2017-11-14 10:38 ` Gregory Maxwell 2017-11-14 10:07 ` Peter Todd 2017-12-04 17:17 ` Andrew Poelstra 2 siblings, 1 reply; 6+ messages in thread From: Peter Todd @ 2017-11-14 9:11 UTC (permalink / raw) To: Gregory Maxwell, Bitcoin Protocol Discussion [-- Attachment #1: Type: text/plain, Size: 2736 bytes --] On Tue, Nov 14, 2017 at 01:21:14AM +0000, Gregory Maxwell via bitcoin-dev wrote: > Jump to "New things here" if you're already up to speed on CT and just > want the big news. <snip> > This work also allows arbitrarily complex conditions to be proven in > the values, not just simple ranges, with proofs logarithmic in the > size of the arithmetic circuit representing the conditions being > proved--and still with no trusted setup. As a result it potentially > opens up many other interesting applications as well. > > The pre-print on this new work is available at https://eprint.iacr.org/2017/1066 Re: section 4.6, "For cryptocurrencies, the binding property is more important than the hiding property. An adversary that can break the binding property of the commitment scheme or the soundness of the proof system can generate coins out of thin air and thus create uncontrolled but undetectable inflation rendering the currency useless. Giving up the privacy of a transaction is much less harmful as the sender of the transaction or the owner of an account is harmed at worst." I _strongly_ disagree with this statement and urge you to remove it from the paper. The worst-case risk of undetected inflation leading to the destruction of a currency is an easily quantified risk: at worst any given participant loses whatever they have invested in that currency. While unfortunate, this isn't a unique or unexpected risk: cryptocurrencies regularly lose 50% - or even 90% - of their value due to fickle markets alone. But cryptocurrency owners shrug these risks off. After all, it's just money, and diversification is an easy way to mitigate that risk. But a privacy break? For many users _that_ threatens their very freedom, something that's difficult to even put a price on. Furthermore, the risk of inflation is a risk that's easily avoided: at a personal level, sell your holdings in exchange for a less risky system; at a system-wide level, upgrade the crypto. But a privacy leak? Once I publish a transaction to the world, there's no easy way to undo that act. I've committed myself to trusting the crypto indefinitely, without even a sure knowledge of what kind of world I'll live in ten years down the road. Sure, my donation to Planned Parenthood or the NRA might be legal now, but will it come back to haunt me in ten years? Fortunately, as section 4.6 goes on to note, Bulletproofs *are* perfectly hiding. But that's a feature we should celebrate! The fact that quantum computing may force us to give up that essential privacy is just another example of quantum computing ruining everything, nothing more. -- https://petertodd.org 'peter'[:-1]@petertodd.org [-- Attachment #2: Digital signature --] [-- Type: application/pgp-signature, Size: 455 bytes --] ^ permalink raw reply [flat|nested] 6+ messages in thread
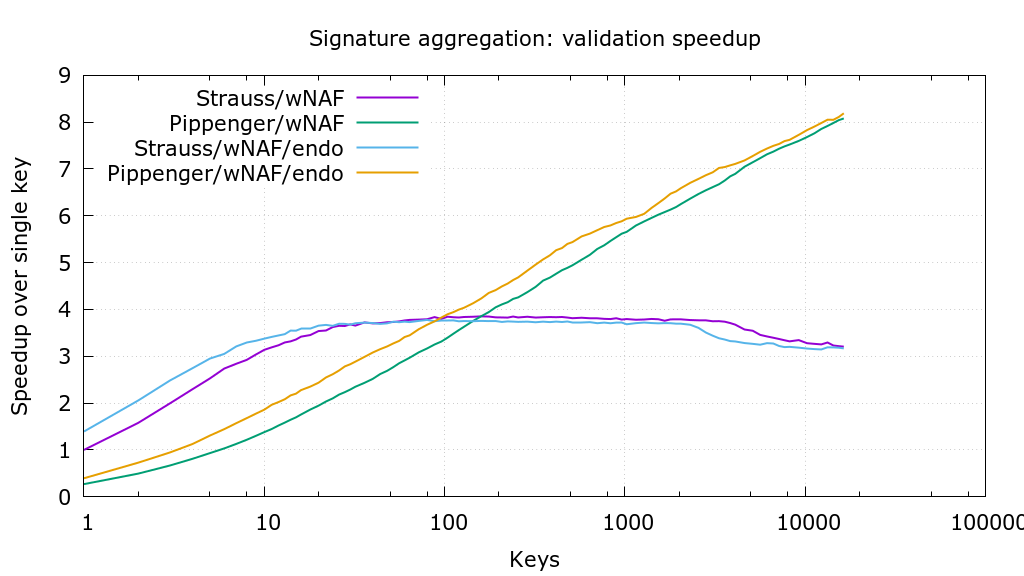
* Re: [bitcoin-dev] Updates on Confidential Transactions efficiency 2017-11-14 9:11 ` Peter Todd @ 2017-11-14 10:38 ` Gregory Maxwell 2017-11-14 10:51 ` Gregory Maxwell 0 siblings, 1 reply; 6+ messages in thread From: Gregory Maxwell @ 2017-11-14 10:38 UTC (permalink / raw) To: Peter Todd; +Cc: Bitcoin Protocol Discussion On Tue, Nov 14, 2017 at 9:11 AM, Peter Todd <pete@petertodd•org> wrote: > I _strongly_ disagree with this statement and urge you to remove it from the > paper. I very strongly disagree with your strong disagreement. > The worst-case risk of undetected inflation leading to the destruction of a > currency is an easily quantified risk: at worst any given participant loses > whatever they have invested in that currency. While unfortunate, this isn't a > unique or unexpected risk: cryptocurrencies regularly lose 50% - or even 90% - > of their value due to fickle markets alone. But cryptocurrency owners shrug > these risks off. After all, it's just money, and diversification is an easy way > to mitigate that risk. > > But a privacy break? For many users _that_ threatens their very freedom, > something that's difficult to even put a price on. Its important that people know and understand what properties a system has. Perhaps one distinction you miss is that perfectly hiding systems don't even exist in practice: I would take a bet that no software on your system that you can use with other people actually implements a perfectly hiding protocol (much less find on most other people's system system :)). In the case of practical use with CT perfect hiding is destroyed by scalability-- the obvious construction is a stealth address like one where a DH public key is in the address and that is used to scan for your payments against a nonce pubkey in the transactions. The existence of that mechanism destroys perfect hiding. No scheme that can be scanned using an asymmetric key is going to provide perfect hiding. Now, perhaps what you'd like is a system which is not perfect hiding but where the hiding rests on less "risky" assumptions. That is something that can plausibly be constructed, but it's not itself incompatible with unconditional soundness. As referenced in the paper, there is also the possibility of having a your cake and eating it too-- switch commitments for example allow having computational-hiding-depending-on-the-hardness-of-inverting-hashes (which I would argue is functionally as good as perfect hiding, esp since hiding is ultimately limited by the asymmetric crypto used for discovery) and yet it retains an option to upgrade or block spending via unsound mechanisms in the event of a crypto break. > Furthermore, the risk of inflation is a risk that's easily avoided: Sounds like you are assuming that you know when there is a problem, if you do then the switch commitments scheme works and doesn't require any selling of anything. Selling also has the problem that everyone would want to do it at once if there was a concern; this would not have good effects. :) Without switch commitments though, you are just hosed. And you cannot have something like switch commitments without abandoning perfect hiding ( though you get hiding which is good enough (tm), as mentioned above). On Tue, Nov 14, 2017 at 10:07 AM, Peter Todd <pete@petertodd•org> wrote: > Re: the unprunable accumulators, that doesn't need to be an inherent property > of Zcash/Monero style systems. > > It'd be quite feasible to use accumulator epochs and either make unspent coins > in a previous epoch unspendable after some expiry time is reached - allowing Miners to reduce coin supply, enhancing the value of their own holdings, by simply not letting near-expiry ones get spent... (This can be partially mediated by constructing proofs to hide if a coins in near expiration or not.) > or make use of a merkelized key-value scheme with transaction provided proofs to shift the costs of > maintaining the accumulator to wallets. Yes, that they can do-- though with the trade-offs inherent in that. It is worse than what you were imagining in the Bitcoin case because you cannot use one or two time-ordered trees, the spent coins list needs search-insertion; so maintaining it over time is harder. :( The single time ordered tree trick doesn't work because you can't mutate the entries without blowing anonymity. I think it's still fair to say that ring-in and tree-in approaches (monero, and zcash) are fundamentally less scalable than CT+valueshuffle, but more private-- though given observations of Zcash behavior perhaps not that much more private. With the right smart tricks the scalablity loss might be more inconvenient than fatal, but they're still a loss even if they're one that makes for a good tradeoff. As an aside, you shouldn't see Monero as entirely distinct now that we're talking about a framework which is fully general: Extending this to a traceable 1 of N input for monero is simple-- and will add size log() in the number of ring inputs with good constant factors. One could also store inputs in a hash tree, and then have a bulletproof that verified membership in the tree. This would provide tree-in style transactions with proofs that grow with the log() of the size of the tree (and a spent coins accumulator); the challenge there would be choosing a hash function that had a compact representation in the arithmetic circuit so that the constant factors aren't terrible. Effectively that's what bulletproofs does: It takes a general scheme for ZKP of arbitrary computation, which could implement a range proof by opening the commitments (e.g. a circuit for EC point scalar multiply) and checking the value, and optimizes it to handle the commitments more directly. If you're free to choose the hash function there may be a way to make a hash tree check ultra efficient inside the proof, in which case this work could implement a tree-in scheme like zcash-- but with larger proofs and slower verification in exchange for much better crypto assumptions and no trusted setup. This is part of what I meant by it opening up "many other interesting applications". But as above, I think that the interactive-sparse-in (CJ) has its own attractiveness, even though it is not the strongest for privacy. ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: [bitcoin-dev] Updates on Confidential Transactions efficiency 2017-11-14 10:38 ` Gregory Maxwell @ 2017-11-14 10:51 ` Gregory Maxwell 0 siblings, 0 replies; 6+ messages in thread From: Gregory Maxwell @ 2017-11-14 10:51 UTC (permalink / raw) To: Peter Todd; +Cc: Bitcoin Protocol Discussion On Tue, Nov 14, 2017 at 10:38 AM, Gregory Maxwell <greg@xiph•org> wrote: > I think it's still fair to say that ring-in and tree-in approaches > (monero, and zcash) are fundamentally less scalable than > CT+valueshuffle, but more private-- though given observations of Zcash While I'm enumerating private transaction topologies there is fourth one I'm aware of (most closely related to ring-in): take N inputs, write >= N outputs, where some coins are spent and replaced with a new output, or an encrypted dummy... and other coins are simply reencrypted in a way that their owner can still decode. Provide a proof that shows you did this faithfully. So this one avoids the spent coins list by being able to malleiate the inputs. We never previously found an efficient way to construct that one in a plain DL setting, but it's probably possible w/ bulletproofs, at least for some definition of efficient. ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: [bitcoin-dev] Updates on Confidential Transactions efficiency 2017-11-14 1:21 [bitcoin-dev] Updates on Confidential Transactions efficiency Gregory Maxwell 2017-11-14 9:11 ` Peter Todd @ 2017-11-14 10:07 ` Peter Todd 2017-12-04 17:17 ` Andrew Poelstra 2 siblings, 0 replies; 6+ messages in thread From: Peter Todd @ 2017-11-14 10:07 UTC (permalink / raw) To: Gregory Maxwell, Bitcoin Protocol Discussion [-- Attachment #1: Type: text/plain, Size: 1532 bytes --] On Tue, Nov 14, 2017 at 01:21:14AM +0000, Gregory Maxwell via bitcoin-dev wrote: > The primary advantage of this approach is that it can be constructed > without any substantial new cryptographic assumptions (e.g., only > discrete log security in our existing curve), that it can be high > performance compared to alternatives, that it has no trusted setup, > and that it doesn't involve the creation of any forever-growing > unprunable accumulators. All major alternative schemes fail multiple > of these criteria (e.g., arguably Zcash's scheme fails every one of > them). Re: the unprunable accumulators, that doesn't need to be an inherent property of Zcash/Monero style systems. It'd be quite feasible to use accumulator epochs and either make unspent coins in a previous epoch unspendable after some expiry time is reached - allowing the spent coin accumulator data to be discarded - or make use of a merkelized key-value scheme with transaction provided proofs to shift the costs of maintaining the accumulator to wallets. The disadvantage of epoch schemes is of course a reduced k-anonymity set, but if I understand the Confidential Transactions proposals correctly, they already have a significantly reduced k-anonymity set per transaction than Zcash theoretically could (modulo it's in practice low anonymity set due to lack of actual usage). In that respect, epoch size is simply a tradeoff between state size and k-anonymity set size. -- https://petertodd.org 'peter'[:-1]@petertodd.org [-- Attachment #2: Digital signature --] [-- Type: application/pgp-signature, Size: 455 bytes --] ^ permalink raw reply [flat|nested] 6+ messages in thread
* Re: [bitcoin-dev] Updates on Confidential Transactions efficiency 2017-11-14 1:21 [bitcoin-dev] Updates on Confidential Transactions efficiency Gregory Maxwell 2017-11-14 9:11 ` Peter Todd 2017-11-14 10:07 ` Peter Todd @ 2017-12-04 17:17 ` Andrew Poelstra 2 siblings, 0 replies; 6+ messages in thread From: Andrew Poelstra @ 2017-12-04 17:17 UTC (permalink / raw) To: Bitcoin Protocol Discussion [-- Attachment #1: Type: text/plain, Size: 8189 bytes --] To follow up on the remarkable work Greg announced from Benedikt Bünz (Stanford) and Jonathan Bootle (UCL) on Bulletproofs: https://eprint.iacr.org/2017/1066 Summary ========= Over the last couple weeks, along with Jonas Nick, Pieter Wuille, Greg Maxwell and Peter Dettmann, I've implemented the single-output version of Bulletproofs at https://github.com/ElementsProject/secp256k1-zkp/pull/16 and have some performance numbers. All of these benchmarks were performed on one core of an Intel i7-6820MQ throttled to 2.00Ghz, and reflect verification of a single 64-bit rangeproof. Old Rangeproof 14.592 ms with endo 10.304 ms Bulletproof 4.208 ms with endo 4.031 ms ECDSA verify 0.117 ms with endo 0.084 ms Here "with endo" refers to use of the GLV endomorphism supported by the curve secp256k1, which libsecp256k1 (and therefore Bitcoin) supports but does not enable by default, out of an abundance of caution regarding potential patents. As we can see, without the endomorphism this reflects a 3.47x speedup over the verification speed of the old rangeproofs. Because Bulletproof verification scales with O(N/log(N)) while the old rangeproof scales with O(N), we can extrapolate forward to say that a 2-output aggregate would verify with 4.10x the speed of the old rangeproofs. By the way, even without aggregation, we can verify two rangeproofs nearly 15% faster than verifying one twice (so a 3.95x speedup) because the nature of the verification equation makes it amenable to batch verification. This number improves with the more proofs that you're verifying simultaneously (assuming you have enough RAM), such that for example you can batch-verify 10000 bulletproofs 9.9 times as fast as you could verify 10000 of the old proofs. While this is a remarkable speedup which greatly improves the feasibility of CT for Bitcoin (though still not to the point where I'd expect a serious proposal to get anywhere, IMHO), the concerns highlighted by Greg regarding unconditional versus computational soundness remain. I won't expand on that more than it has already been discussed in this thread, I just want to tamp down any irrational exhuberance about these result. People who only care about numbers can stop reading here. What follows is a discussion about how this speedup is possible and why we weren't initially sure that we'd get any speedup at all. Details ========= Section 6 of the linked preprint discusses performance vs our old rangeproofs. As Greg mentioned, it is possible to fit two 64-bit bulletproofs into 738 bytes, with logarithmic scaling. (So one proof would take 674 bytes, but eight proofs only 866 bytes.) However, this section does not give performance numbers, because at the time the preprint was written, there was no optimized implementation on which to benchmark. It was known that verification time would be roughly linear in the size of the proof: 141 scalar-multiplies for a 64-bit proof, 270 for an aggregate of two proofs, and so on [*]. Our old rangeproofs required only 128 multiplies for a 64-bit proof, then 256 for two, and so on. So naively we were concerned that the new Bulletproofs, despite being fantastically smaller than the original rangeproofs, might wind up taking a bit longer to verify. For reference, an ordinary ECDSA signature verification involves 2 multiplies. So roughly speaking, the naive expectation was that a N-bit rangeproof would require N-many signature verifications' worth of CPU time, even with this new research. Worse, we initially expected bulletproofs to require 1.5x this much, which we avoided with a trick that I'll describe at the end of this mail. As you can see in the above numbers, the old rangeproofs actually perform worse than this expectation, while the new Bulletproofs perform significantly **better**. These are for the same reason: when performing a series of scalar multiplications of the form a*G + b*H + c*I + ... where G, H, I are curvepoints and a, b, c are scalars, it is possible to compute this sum much more quickly than simply computing a*G, b*H, c*I separately and then adding the results. Signature validation takes advantage of this speedup, using a technique called Strauss' algorithm, to compute the sum of two multiplies much faster than twice the multiple-speed. Similarly, as we have learned, the 141 scalar-multiplies in a single-output Bulletproof can also be done in a single sum. To contrast, the old rangeproofs required we do each multiplication separately, as the result of one would be hashed to determine the multiplier for the next. libsecp256k1 has supported Strauss' algorithm for two points since its inception in 2013, since this was needed for ECDSA verification. Extending it to many points was a nontrivial task which Pieter, Greg and Jonas Nick took on this year as part of our aggregate signatures project. Of the algorithms that we tested, we found that Strauss was fastest up to about 100 points, at which point Pippenger's was fastest. You can see our initial benchmarks here https://user-images.githubusercontent.com/2582071/32731185-12c0f108-c881-11e7-83c7-c2432b5fadf5.png though this does not reflect some optimizations from Peter Dettmann in the last week. It was a happy coincidence that the Bulletproofs paper was published at nearly the same time that we had working multi-point code to test with. Finally, the Bulletproof verification process, as written in the paper, is a recursive process which does not appear to be expressible as a single multiproduct, and in fact it appears to require nearly twice as many multiplications as I claim above. I want to draw attention to two optimizations in particular which made this possible. 1. By expanding out the recursive process, one can see that the inner-product argument (Protocol 1 in the paper) is actually one multiproduct: you hash each (L_i, R_i) pair to obtain logarithmically many scalars, invert these, and then each scalar in the final multiproduct is a product containing either the inverse or original of each scalar. Peter Dettmann found a way to reduce this to one scalar inversion, from which every single scalar was obtainable from a single multiplication or squaring of a previous result. I was able to implement this in a way that cached only log-many previous results. 2. Next, line (62) of the Bulletproofs paper appears to require N multiplications beyond the 2N multiplications already done in the recursive step. But since these multiplications used the same basepoints that were used in the recursive step, we could use the distributive property to combine them. This sounds trivial but took a fair bit of care to ensure that all the right data was still committed to at the right stage of proof verification. Further Work ========= There are still a few open issues I plan to help resolve in the coming month: - Bulletproof aggregation is not compatible with Confidential Assets, where each output has a unique asset tag associated with it. There are a couple possible solutions to this but nothing public-ready. - Bulletproofs, as described in the paper, work only when proving 2^n-many bits. I believe there is a straightforward and verifier-efficient way to extend it to support non-powers-of-2, but this requires some work to modify the proof in the paper. - Bulletproofs are actually much more general than rangeproofs. They can be used to prove results of arbitrary arithmetic circuits, which is something we are very interested in implementing. [*] By "and so on", I mean that N bits require 2N + 2log_2(N) + 6 scalar multiplies. Cheers Andrew -- Andrew Poelstra Mathematics Department, Blockstream Email: apoelstra at wpsoftware.net Web: https://www.wpsoftware.net/andrew "A goose alone, I suppose, can know the loneliness of geese who can never find their peace, whether north or south or west or east" --Joanna Newsom [-- Attachment #2: signature.asc --] [-- Type: application/pgp-signature, Size: 455 bytes --] ^ permalink raw reply [flat|nested] 6+ messages in thread
end of thread, other threads:[~2017-12-04 17:27 UTC | newest] Thread overview: 6+ messages (download: mbox.gz / follow: Atom feed) -- links below jump to the message on this page -- 2017-11-14 1:21 [bitcoin-dev] Updates on Confidential Transactions efficiency Gregory Maxwell 2017-11-14 9:11 ` Peter Todd 2017-11-14 10:38 ` Gregory Maxwell 2017-11-14 10:51 ` Gregory Maxwell 2017-11-14 10:07 ` Peter Todd 2017-12-04 17:17 ` Andrew Poelstra
This is a public inbox, see mirroring instructions for how to clone and mirror all data and code used for this inbox
{kind=link}